Bull Usage Tutorial
Basic Concepts
What is Bull?
Task queues are generally used for asynchronously processing time-consuming tasks such as video transcoding and sending SMS messages, preventing API connection timeouts.
Bull is a Node library that implements a fast and powerful queue system based on redis.
Although it is possible to implement a queue using direct Redis commands, this library provides an API that handles all the underlying details and enriches the basic functionality of Redis, making it easy to handle more complex use cases.
If you are not familiar with queues, you might wonder why you need them. Queues can elegantly solve many different problems, such as creating robust communication channels between microservices to smoothly handle CPU peaks, or distributing heavy work from one server to many smaller work intervals.
Getting Started
Install Bull:
$ npm install bull --save && npm install @types/bull --save-dev
or
$ yarn add bull && yarn add --dev @types/bull
To use bull, you must first install Redis. For local development, docker can conveniently install it. Bull defaults to connecting to Redis at localhost:6379.
Simple Queue
Creating a queue is as simple as instantiating a Bull instance:
const myFirstQueue = new Bull('my-first-queue');
A queue instance typically has three main roles: task producers, task consumers, or event listeners.
Although a given instance can serve all three roles, producers and consumers are usually created as multiple instances. By referring to it through the instantiated name of the queue (such as my-first-queue in the example above), a queue can have many producers, many consumers, and many listeners. An important aspect is that producers can add tasks to the queue even if there are no consumers available at the time: the queue provides asynchronous communication, which is one of the features that make them so powerful.
On the other hand, you can have one or more consumers process tasks from the queue, which will be consumed in the specified order: FIFO (default), LIFO, or based on priority.
Regarding work intervals, they can run in the same or different processes, on the same machine or in a cluster. Redis serves as a common endpoint, and as long as consumers or producers can connect to Redis, they will be able to cooperate to process tasks.
Producers
Task producers are simply some Node programs that add tasks to the queue, such as:
const myFirstQueue = new Bull('my-first-queue');
const job = await myFirstQueue.add({
foo: 'bar',
});
As you can see, a task is simply a JavaScript object. This object must be serializable, more specifically it should be convertible to a string by JSON.stringify, because that is the form in which it is stored in Redis.
You can also provide an options object parameter after the task data object parameter, which we will introduce later.
Consumers
Consumers, or workers, are nothing more than a Node program that defines a process function, such as:
const myFirstQueue = new Bull('my-first-queue');
myFirstQueue.process(async (job) => {
return doSomething(job.data);
});
The process function of the task is called every time the worker is idle and there are tasks waiting to be processed in the queue. Since consumers do not need to be online when tasks are added (adding and consuming are asynchronous), many tasks will accumulate in the queue waiting to be consumed until they are all processed.
In the example above, we define the process function as async, which is strongly recommended. If your Node runtime does not support async/await, then you simply need to return a Promise at the end of the process function to achieve a similar result.
The value returned by the process function will be stored in the task job instance, which is convenient for later access, for example, in the completed event of the listener, you can access the job instance through the progress function:
myFirstQueue.process(async (job) => {
let progress = 0;
for (i = 0; i < 100; i++) {
await doSomething(job.data);
progress += 10;
job.progress(progress);
}
});
Listeners
Finally, you can listen for events triggered in the queue. If it is a local listener, it only receives notifications generated within the specified queue instance, and if it is a global listener, it listens for all events of the specified queue. Therefore, you can add listeners to any instance, even instances that act as consumers or producers. However, please note that if the queue is not a consumer or producer, local events will never be triggered, in which case you need to use global events.
const myFirstQueue = new Bull('my-first-queue');
// Define a local completed event
myFirstQueue.on('completed', (job, result) => {
console.log(`Job completed with result ${result}`);
});
Lifecycle
To make full use of the potential of Bull queues, it is important to understand the lifecycle of tasks. From the moment the producer calls the add method on the queue instance, the task enters a lifecycle that will be in different states until it is completed or fails (although technically failed tasks can be retried and given a new lifecycle).
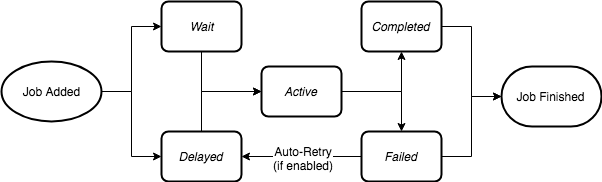
When a task is added to the queue, it can be in a waiting state or a delayed state. The waiting state is actually a waiting list, and all queues are in a waiting state before processing, and the delayed state means that the task is waiting for some timeout or processing of a failed task, and delayed tasks will not be processed directly, but will be placed at the beginning of the waiting list and processed when the worker is idle.
The next state of the task is the "active" state. The active state is represented by a Redis set, which is the task currently being processed, and at this time they are running in the process function. A task can be in the active state for an unlimited period of time until the process is completed or an exception is raised, so that the task ends with a "completed" or "failed" state.
Stalled Jobs
In Bull, we define the concept of stalled jobs. Stalled jobs are tasks that are being processed, but Bull suspects that the process function is suspended. When the task being processed by the process function is too CPU-intensive, it will cause the worker to be unable to tell the queue that it is still processing the task, resulting in a stalled job.
When a job is stalled, depending on the job's settings, the job can be retried by other idle workers or switched to a failed state.
Stalled jobs can be avoided by ensuring that the process function does not run for too long in the Node event loop, or by using separate sandbox processors.
Events
Queues in Bull have several events that are useful in many use cases. Events can be local to a queue instance (a worker), for example, if a task is completed within a given worker, then a local event will be emitted only for that instance. However, you can listen to all events, for example, by prefixing the local event name with global:. Then, we can listen to all events generated by all workers of a specified queue.
A local completed event:
queue.on('completed', (job) => {
console.log(`Job with id ${job.id} has been completed`);
});
And the following can be listened to globally:
queue.on('global:completed', (jobId) => {
console.log(`Job with id ${jobId} has been completed`);
});
Note that the signature of global events is slightly different from that of local events, in the example above, it only sends the ID of the task rather than the complete instance of the task itself, this is for performance reasons.
A list of available events can be found in the [reference documentation] (https://github.com/OptimalBits/bull/blob/master/REFERENCE.md#eventsk).
Queue Options
Queues can be instantiated with some options, for example, you can specify the address of the Redis server and password, as well as some other useful settings. All these settings can be found in Bull's reference documentation, let's look at some
For more detailed API information, please refer to the documentation
Rate Limiting
Limit the number of jobs processed by the created queue within a time unit. The limit is defined per queue and is independent of the number of worker intervals, so you can scale horizontally and still easily limit the processing rate:
// Limit queue to max 1.000 jobs per 5 seconds.
const myRateLimitedQueue = new Queue('rateLimited', {
limiter: {
max: 1000,
duration: 5000,
},
});
When the queue reaches its rate limit, the requested jobs will be added to the delayed queue.
Named Jobs
Naming jobs does not change any mechanisms of the queue but can result in clearer code and better visualization in UI tools:
// Jobs producer
const myJob = await transcoderQueue.add('image', { input: 'myimagefile' });
const myJob = await transcoderQueue.add('audio', { input: 'myaudiofile' });
const myJob = await transcoderQueue.add('video', { input: 'myvideofile' });
// Worker
transcoderQueue.process('image', processImage);
transcoderQueue.process('audio', processAudio);
transcoderQueue.process('video', processVideo);
Remember, each queue instance must have a single processor for each named job, otherwise, an exception will be thrown.
Sandbox Processors
As mentioned above, when defining the process function, you can also provide a concurrency setting. This setting allows workers to process multiple jobs in parallel. Jobs are still processed in the same Node process, even if the processing is IO-intensive.
However, sometimes you need to process CPU-intensive tasks that could lock the Node event loop for too long, causing Bull to potentially stop the job. To avoid this situation, you can run the process function in a separate Node process. In this case, the concurrency parameter will determine the maximum number of concurrent processes allowed.
We call such processes "sandbox" processes, so even if a process crashes, it will not affect any other processes, and a new process will be automatically generated to replace it.
Job Types
The default job type in Bull is "FIFO" (First In, First Out), which means that jobs are processed in the same order they enter the queue. This is useful when you want to process tasks in a different order.
LIFO
LIFO (Last In, First Out) means that jobs are added to the front of the queue and will be processed when a worker is idle.
const myJob = await myqueue.add({ foo: 'bar' }, { lifo: true });
Delays
Delay jobs from being processed for a certain period of time. Note that the delay parameter represents the minimum amount of time the job should wait before being processed. When the delay time expires, the job will move to the front of the queue and be processed when a worker is idle.
// Delayed 5 seconds
const myJob = await myqueue.add({ foo: 'bar' }, { delay: 5000 });
Priorities
Jobs can be assigned priorities. Jobs with higher priorities will be processed before jobs with lower priorities. The highest priority is 1, and the larger the number, the lower the priority. Remember that priority queues are slightly slower than standard queues (because the current insertion time of the priority queue O(n) will replace the standard queue's O(1)).
The n in the parentheses above represents the number of tasks currently waiting in the queue.
const myJob = await myqueue.add({ foo: 'bar' }, { priority: 3 });
Repeatable Jobs
Repeatable jobs are special jobs that can be repeated indefinitely according to cron specifications or time intervals until a given maximum time or number of repetitions is reached (if either is set).
// Repeat every 10 seconds for 100 times.
const myJob = await myqueue.add(
{ foo: 'bar' },
{
repeat: {
every: 10000,
limit: 100,
},
}
);
// Repeat payment job once every day at 3:15 (am)
paymentsQueue.add(paymentsData, { repeat: { cron: '15 3 * * *' } });
There are some important notes about repeatable jobs:
- If the repeat options are the same, Bull will not add the same repeatable job. (Note: The job ID is part of the repeat options, because:https://github.com/OptimalBits/bull/pull/603,so passing the job ID will allow inserting a job with the same cron in the queue)
- If there is no running worker, repeatable jobs will not accumulate until the next worker is online.
- Repeatable jobs can be deleted using the removeRepeatablemethod.
How to Use
Basic Usage
var Queue = require('bull');
var videoQueue = new Queue('video transcoding', 'redis://127.0.0.1:6379');
var audioQueue = new Queue('audio transcoding', { redis: { port: 6379, host: '127.0.0.1', password: 'foobared' } }); // Specify Redis connection using object
var imageQueue = new Queue('image transcoding');
var pdfQueue = new Queue('pdf transcoding');
videoQueue.process(function (job, done) {
// job.data contains the custom data passed when the job was created
// job.id contains id of this job.
// transcode video asynchronously and report progress
job.progress(42);
// call done when finished
done();
// or give a error if error
done(new Error('error transcoding'));
// or pass it a result
done(null, { framerate: 29.5 /* etc... */ });
// If the job throws an unhandled exception it is also handled correctly
throw new Error('some unexpected error');
});
audioQueue.process(function (job, done) {
// transcode audio asynchronously and report progress
job.progress(42);
// call done when finished
done();
// or give a error if error
done(new Error('error transcoding'));
// or pass it a result
done(null, { samplerate: 48000 /* etc... */ });
// If the job throws an unhandled exception it is also handled correctly
throw new Error('some unexpected error');
});
imageQueue.process(function (job, done) {
// transcode image asynchronously and report progress
job.progress(42);
// call done when finished
done();
// or give a error if error
done(new Error('error transcoding'));
// or pass it a result
done(null, { width: 1280, height: 720 /* etc... */ });
// If the job throws an unhandled exception it is also handled correctly
throw new Error('some unexpected error');
});
pdfQueue.process(function (job) {
// Processors can also return promises instead of using the done callback
return pdfAsyncProcessor();
});
videoQueue.add({ video: 'http://example.com/video1.mov' });
audioQueue.add({ audio: 'http://example.com/audio1.mp3' });
imageQueue.add({ image: 'http://example.com/image1.tiff' });
Using Promises
You can return promises instead of the done callback function:
videoQueue.process(function (job) {
// don't forget to remove the done callback!
// Simply return a promise
return fetchVideo(job.data.url).then(transcodeVideo);
// Handles promise rejection
return Promise.reject(new Error('error transcoding'));
// Passes the value the promise is resolved with to the "completed" event
return Promise.resolve({ framerate: 29.5 /* etc... */ });
// If the job throws an unhandled exception it is also handled correctly
throw new Error('some unexpected error');
// same as
return Promise.reject(new Error('some unexpected error'));
});
Standalone Processes
The process function can run in a standalone process. This has several advantages:
- The process is a sandbox, so even if it crashes, it will not affect other programs.
- You can run blocking code without affecting the queue (jobs will not be stalled).
- Utilization of multi-core CPUs is much better.
- Fewer connections to Redis.
To run this feature, simply create a separate file:
// processor.js
module.exports = function (job) {
// Do some heavy work
return Promise.resolve(result);
};
And define the processor like this:
// Single process:
queue.process('/path/to/my/processor.js');
// You can use concurrency as well:
queue.process(5, '/path/to/my/processor.js');
// and named processors:
queue.process('my processor', 5, '/path/to/my/processor.js');
Repeatable Jobs
Jobs can be added to the queue and processed repeatedly according to cron specifications:
paymentsQueue.process(function(job){
// Check payments
});
// Repeat payment job once every day at 3:15 (am)
paymentsQueue.add(paymentsData, {repeat: {cron: '15 3 * * *'}});
Check the expression at this link to verify its correctness.
Pause / Resume
A queue can be paused and resumed globally (pass true to pause processing for
just this worker):
queue.pause().then(function () {
// queue is paused now
});
queue.resume().then(function () {
// queue is resumed now
});
Events
The queue will trigger some useful events, for example:
.on('completed', function(job, result){
// Job completed with output result!
})
For information on events (including a full list of triggered events), please refer to the event reference.
Queue Performance
Queues are inexpensive, so if you need many of them, simply create new queues with different names:
var userJohn = new Queue('john');
var userLisa = new Queue('lisa');
.
.
.
However, each queue instance requires a new Redis connection. See how to reuse connections, or you can also use named jobs to achieve similar results.
Cluster Support
For versions 3.2.0 and above, thread processors are recommended.
var Queue = require('bull'),
cluster = require('cluster');
var numWorkers = 8;
var queue = new Queue('test concurrent queue');
if (cluster.isMaster) {
for (var i = 0; i < numWorkers; i++) {
cluster.fork();
}
cluster.on('online', function (worker) {
// Lets create a few jobs for the queue workers
for (var i = 0; i < 500; i++) {
queue.add({ foo: 'bar' });
}
});
cluster.on('exit', function (worker, code, signal) {
console.log('worker ' + worker.process.pid + ' died');
});
} else {
queue.process(function (job, jobDone) {
console.log('Job done by worker', cluster.worker.id, job.id);
jobDone();
});
}
Official Documentation
For complete documentation, please refer to the official wiki.